Historically for CMOS based digital computing the performance of CPUs could be increased with every technology generation through an increase in operating frequency without any additional power consumption. This was possible because as transistors got smaller their power density stayed constant, known as Dennard scaling. The smaller the technology nodes got, the larger got the share of the operating frequency independent leakage power consumption of overall power consumption. The threat of thermal runaways limited the continuation of scaling operating frequencies for more performance, resulting in the breakdown of Dennard scaling. An alternative approach to further increase performance was parallelizing computation on multiple processing cores. Either a single parallelizable process (program) can be split into multiple threads running on different cores in parallel or multiple processes can be executed in parallel to reduce latency.
Limits of parallelization
While many applications benefit from parallelization resulting in a speedup in latency, their performance is still limited by the fraction of an application that cannot be parallelized. This is known as Ahmdal’s law. Imagine the problem of calculating a dot-product of two vectors of size n. For an element-wise multiplication of the vectors n multiplications are needed, which can be completely parallelized since no results depend on each other. But summing up the multiplication results requires a sequential summation of partial sums, allowing for only pairwise parallelization per sequential step resulting in a theoretical lower bound for the speedup.
In hardware this theoretical lower bound cannot easily be assumed to be linearly proportional to the computation time due to the challenge of sharing data (e.g. partial sums of the dot-product) and synchronizing program execution between multiple parallel threads. Especially data intense workloads can suffer from the von-Neumann bottleneck when processing cores share or access data via shared memory. Application specific multi-core processors, like graphic processing units (GPU) or edge ai accelerators, both mainly optimizing for execution of parallel multiply-accumulate (MAC) operations therefore do not only need to consider the usage of application specific processing cores. They also have to consider characteristics of the system implementing communication between the cores consisting of distributed memory hierarchy, network on chip (NoC) architecture, communication protocols and the thereby resulting possible dataflows. Only when considering all these aspects as much speed up through parallelization as possible can be achieved with respect to a specific application. Therefore, hardware concepts are often built in co-design with the applied algorithms for applications such as dataflow computing problems to reduce data movements and sequential bottlenecks for parallelized computations. Most interesting key performance indicators are not the operating frequency or even the number of cores, but rather latency and power consumption for application specific benchmarks. The quality of benchmark related KPIs though relies on the quality of the benchmarks and results can be misleading when variations in benchmark and application result in performance degradations, which are not traceable for a user or require expert knowledge of low-level programming to prevent. Latter can be interpreted as a loss of the high-level abstraction layer of the computing system.
Types of parallelization
Parallelization in computing today is considered on chip, system and network level.
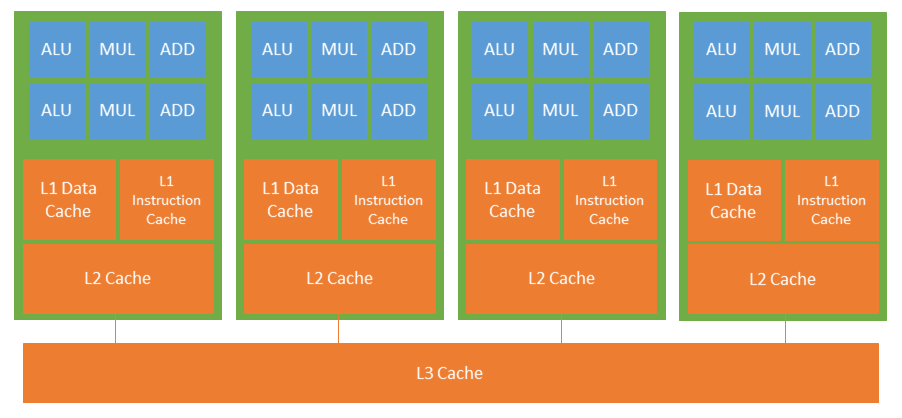
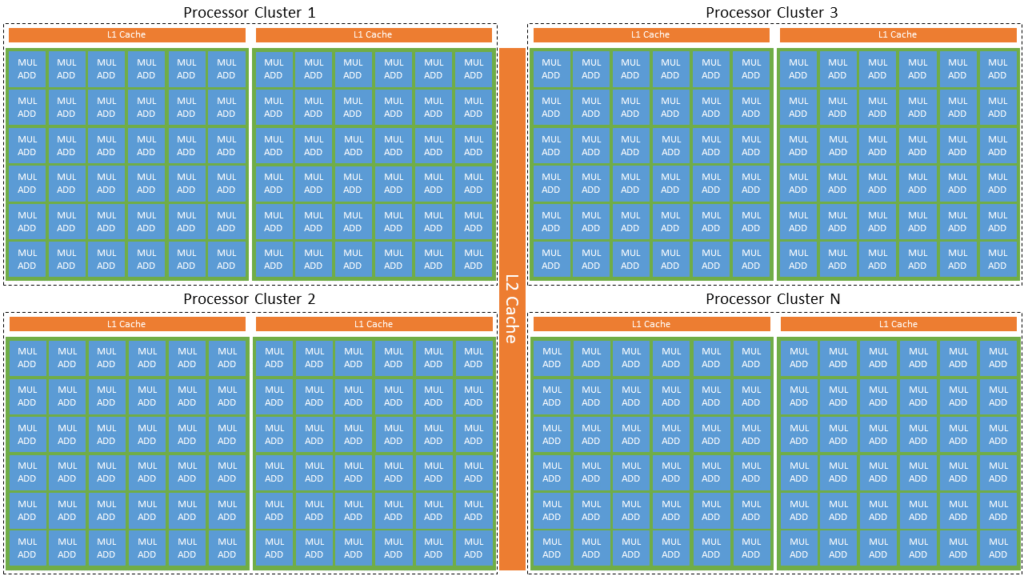
Multi-core processors allow parallelization of single parallelizable tasks or multiple tasks within one chip. Examples are multi-core CPUs for general purpose computing or application specific solutions, like GPUs which use multiply-add processing cores in combination with an optimized dataflow for matrix-vector multiplication. Going beyond this, recently different computational units specified for neural networks were developed, which arrange the processing unit in a matrix to enhance the calculation of matrix or tensor products. Direct data exchange between processing cores or data exchange via on-chip memory can save energy compared to off-chip memory accesses or data transfers. Modern system-on-chips already implement heterogeneous architectures often consisting of one or multiple general-purpose processing cores and one or multiple (different) application specific co-processors to parallelize different tasks efficiently.
On a system level, multiple processing units can be combined to overcome scalability limits with respect to processing cores and memory of on-chip parallelization. Each processing unit could also have multiple processing cores, introducing a first layer of hierarchy in parallelization. Data exchange between processing cores on different chips has higher latency and energy consumption compared to on-chip communication even with high-speed data transfer solutions. The same is true for dedicated or shared off-chip memory accesses, while shared memory can be a potential bottleneck. Compute clusters for high performance computing for example in server farms often combine multiple systems of a heterogeneous set of processors and smart task distribution algorithms are required to optimize the performance, utilization and especially efficiency for task parallelization.
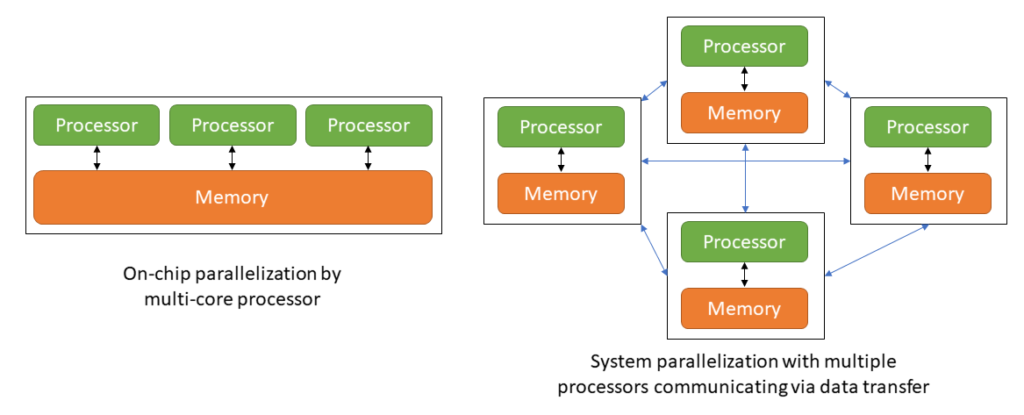
With the emergence of cloud-based computing solutions another hierarchy level was added by combining multiple compute clusters in a network that distributes tasks between multiple clusters. With increasing number of hierarchies and system sizes the overhead of efficient task distribution and parallelization becomes more and more difficult.